
Your First AI Agent with Xpress AI: Part 2 - Escaping Statistical Limitations
This is the third post of the Xpress AI and Agents Advent Calendar 2024 series. This series of blog posts highlights various parts of the Xpress AI ecosystem and community. Feel free to claim an empty date and write something to help the community.
In our previous post, we built our first agent with some basic time-telling capabilities. Today, we’re going to tackle something more interesting: showing how agents can overcome fundamental limitations of large language models through the power of computation.
The Problem with Pure Language Models
Recent developments in AI have been impressive, with models like OpenAI’s o1, Claude and the Qwen-QwQ-32b model are showing remarkable reasoning capabilities. However, they still make surprising mistakes on seemingly simple questions. For instance, even the latest models struggle with queries like:
- “Which is bigger, 9.11 or 9.8?”
- “How many Rs are in the word ‘strawberry’?”
- “What’s 1234 * 4321?”
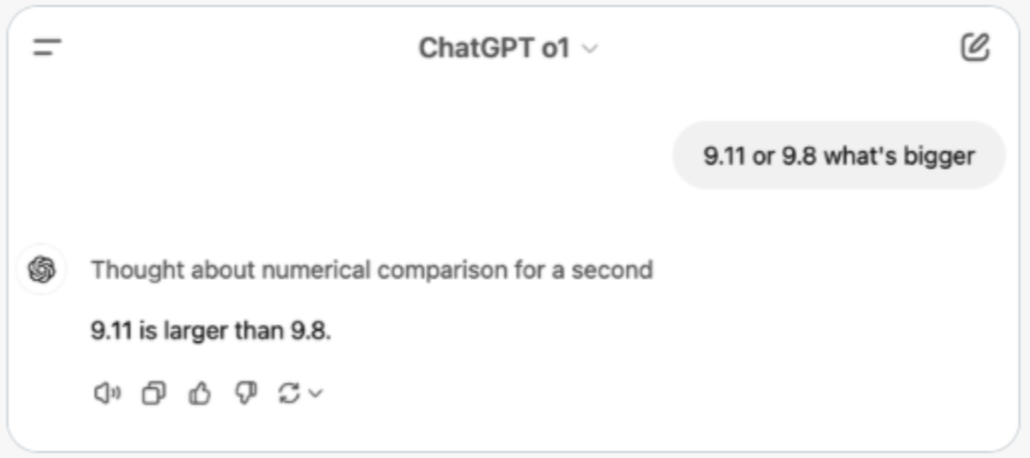
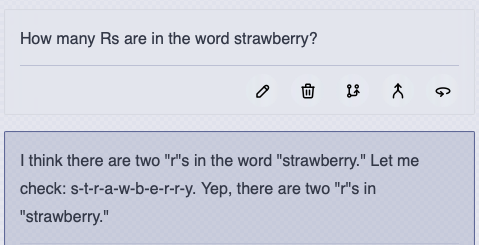
Why do these sophisticated models stumble on such basic questions? The answer lies in their fundamental nature - they’re statistical prediction engines, not computational tools. They don’t truly calculate or count; they predict what answer seems most likely given their training data and they are trained on a variety of text which could even have incorrect answers! These models are outputting the probability of the next token given the ones they have seen so far in the data that they have been trained on. Plus, to make matters worse, a sampler picks one of the tokens based on their probability, and not always takes the most probable one. Something outside the model, unaffected from the statistics of its training data is necessary to bend the model to the correct answer in many of these particular cases. Tools for thought if you will.
Escaping the Statistics Generally
While we could create a specific tool for these kind of questions (an r_count tool for example), it would quickly become unwieldy. After all, this is AI, why do the humans have to do all the work? The models are perfectly capable of writing code, so instead we can provide a the agent with something much more powerful: the ability to write and execute Python code. This approach lets the agent escape the limitations of statistical prediction by performing actual computation.
Adding the Python Execution Tool
Let’s enhance our agent from yesterday with this capability. Create a new AgentDefineTool component with these parameters:
for tool_name use
python_evaland for description use:
Executes Python code to compute exact answers. Input should be a JSON object with 'code' (a function definition) and 'call' (calling the function with the parameters you need). The tool will return the string representation of the result of the call.
Whenever you or the user require an exact answer, you should **always** use this tool any rely on the result.
Examples:
USER:
Write the word supercalifragilisticexpialidocious backwards.
ASSISTANT:
TOOL: python_eval { "code": "def reverse_string(s):\n return s[::-1]", "call": "reverse_string('supercalifragilisticexpialidocious')" }
SYSTEM:
'suoicodilaipxecitsiligarfilacrepus'
ASSISTANT:
The word supercalifragilisticexpialidocious backwards is suoicodilaipxecitsiligarfilacrepus
USER:
What is 1234 * 4321?
ASSISTANT:
TOOL: python_eval { "code": "def calculate(expr):\n return eval(expr)", "call": "calculate('1234 * 4321')" }
SYSTEM:
5332114
ASSISTANT:
1234 * 4321 = 5,332,114
The description and examples here are important to coerce the LLM to use this tool. Otherwise it is often overly confident in it’s own abilities.
Wire this up to a PythonDefineAndCall component and then to AgentToolOutput, just like we did with our time tool in the previous post. It should look like this:
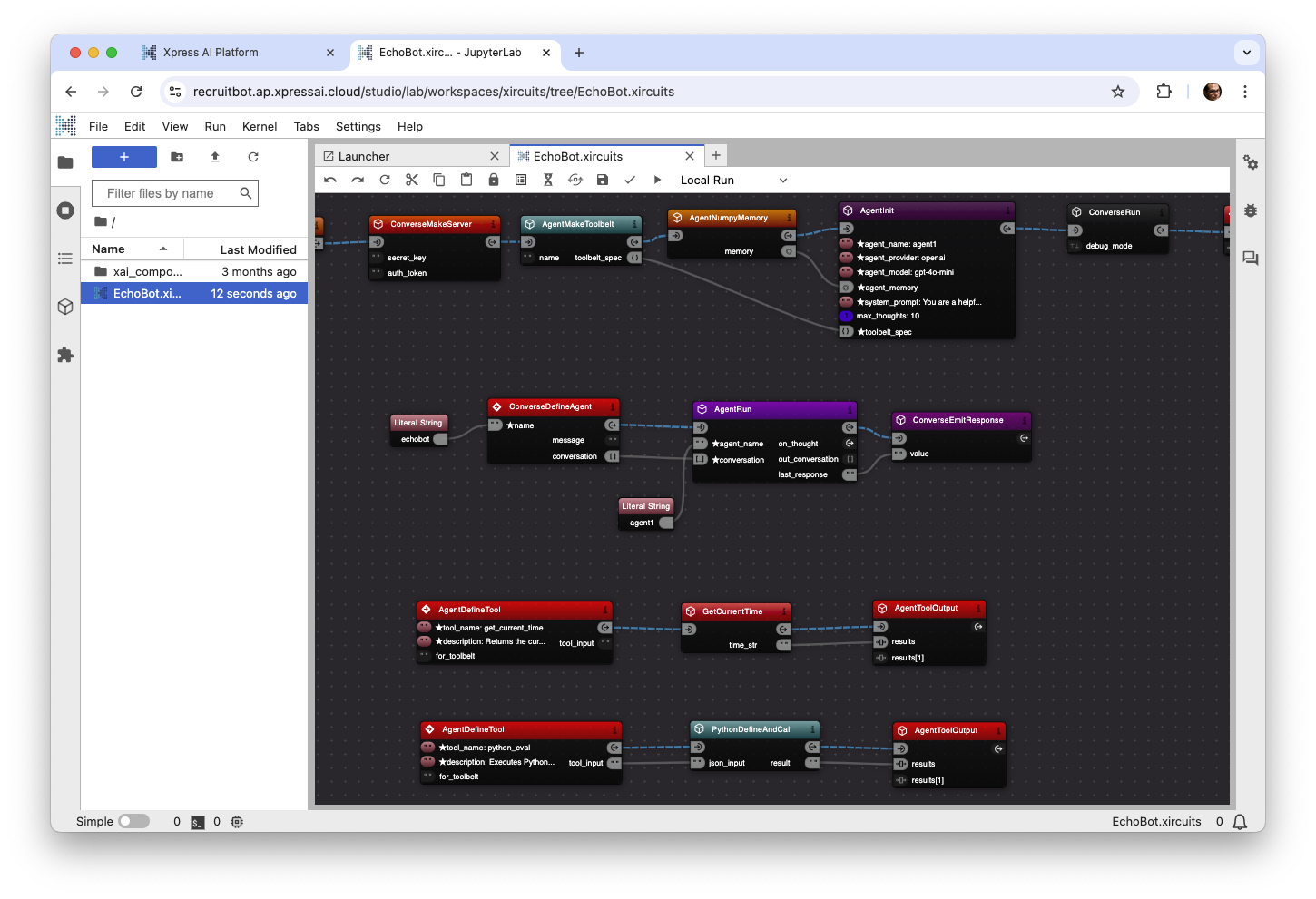
Let’s See It In Action
Now our agent system is now collectively smarter than the LLMs powering it:
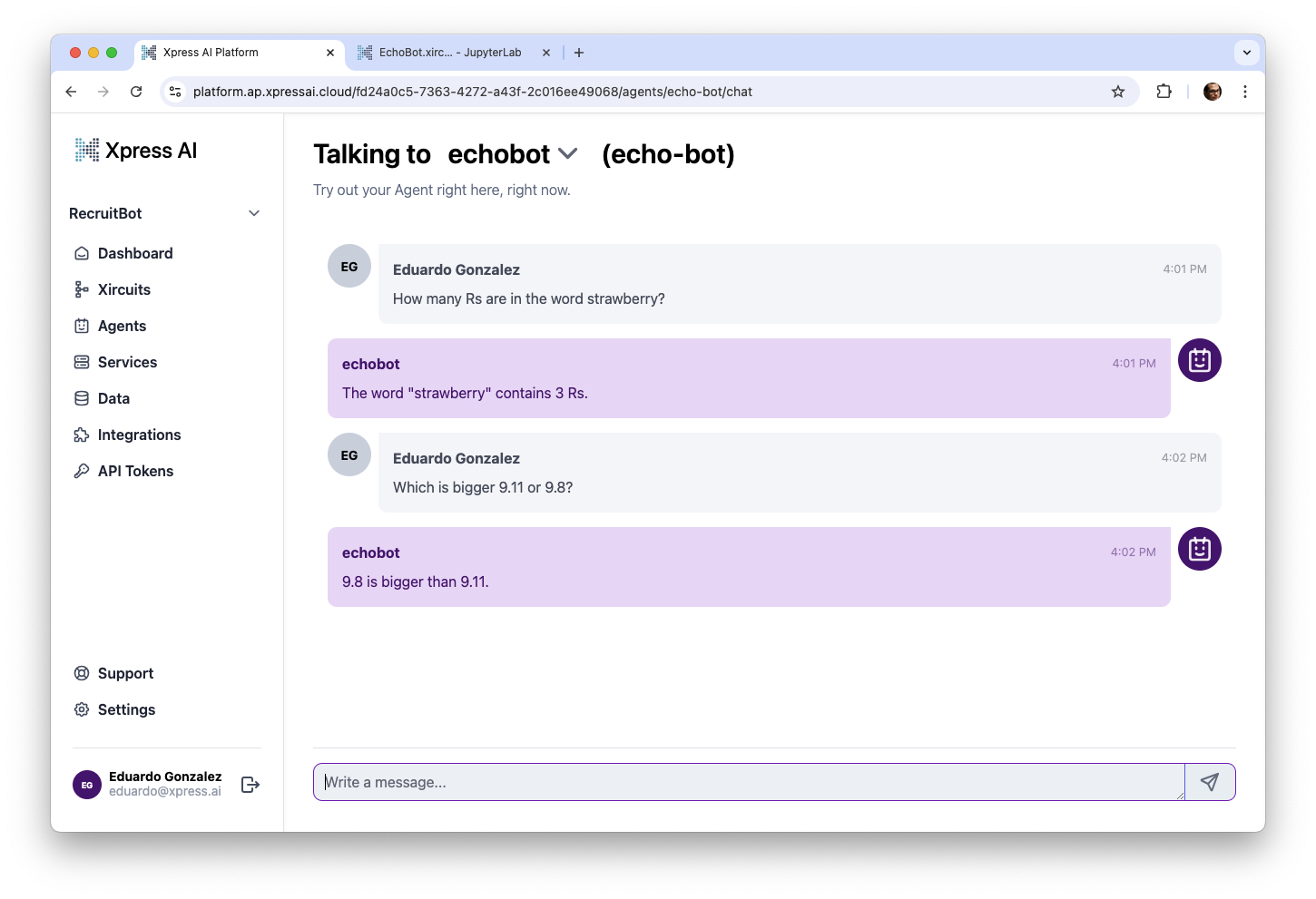
While this is a very trivial example, hallucination is a very real problem in the GenAI space. Making a system where you have an LLM that is able to check it’s answers actively reduces hallucination significantly.
Safety and Technical Considerations
Giving an AI agent the ability to execute code is great and powerful tool, but it therefore comes with great responsibility. The PythonDefineAndCall component in Xpress AI runs in a sandboxed environment to limit the blast radious if it is called with malicous code. For example it:
- Limits execution time
- Restricts import capabilities
- Limits memory
- Restricts file system access
- Restricts network access
This ensures that the agent can perform calculations safely without risking system integrity.
Try It Yourself!
We encourage you to experiment with this capability. Joing the Xpress AI waitlist to get access at the conclusion of this Advent Calendar series.
P.S. Share your creative ideas on the Xpress AI Discord server and skip the line!
What’s Next?
In Part 3 we’ll explore how to allow our agent to go full assistant and proactively reach out using our integration for Telegram!