The main objective in my task is to classify all the text items in the medical documents according to their class category. Due to some insufficient and not available samples for certain classes that I have in this post I will demo how my text classifier model works well on 2 classes with high sample distributions.
Methodology
Basically, this is the main pipeline that I have followed when I develop the Deep Learning model. Details methodology will be described up until the model development.
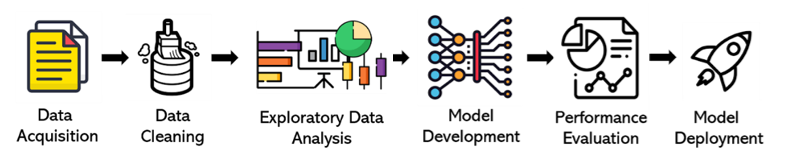
a. Data Acquisition and Data Cleaning
Starting with the data acquisition, my data representation currently in the image document file format. What I need to do is to apply the OCR on the document and extract all the required text items. After that, several steps in the data cleaning and pre-processing need to be applied such as exclude the stop words, noise removal and punctuations before feed into the model training. We want important context for each class category can be captured from the text. However, for some cases, since our text items are related to medical area, we need to remain some of the punctuations for example dash (-) and percentage (%) that is frequently used in the medical items (X-Ray, Covid-19, CT-Scan etc.).
b. Exploratory Data Analysis (EDA)
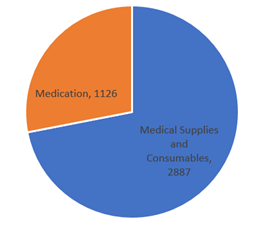
After extract and cleaning the text items, EDA will help us to visualize and summarize current text that we have including word occurrence, sample distributions between classes. As I mentioned just now, I will consider 2 classes in my text classifier demo. From 99 type of hospitals documents, we found most of the items in the medical documents dominant by the category of “Medical Supplies and Consumables” and “Medications” and the sample distributions as follows:
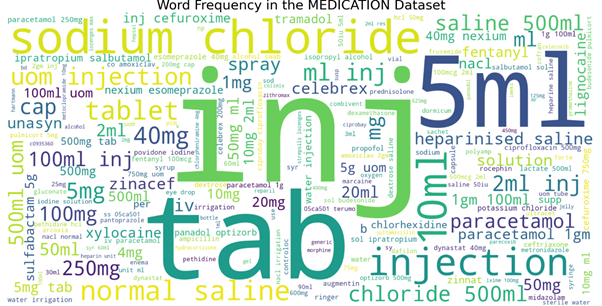
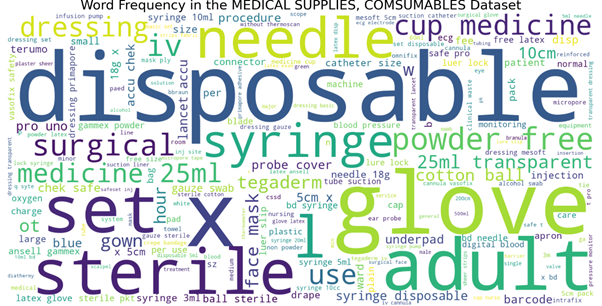
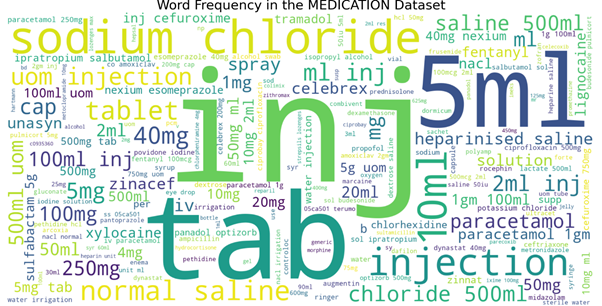
Another thing that we can do to capture more characteristics in our samples is to perform the word cloud. We can visualize what is the most frequent word used in each class category at the same time we can pin-point unnecessary things from the current samples and check again our data cleaning pre-processing. Data quality play an important role in our model training.
c. Model Development
For Deep Learning model architecture, I am creating my baseline model using combination of CNN model with the LSTM model. Where CNN model able to capture important features from the text meanwhile the LSTM layers is used to interpret the features from the contextual text. For the embedding layers, 2 types of embedding can be applied which are word embedding or character embedding. You can utilize some pre-trained embedding on larger corpus (GloVe or word2vec) or train your own embedding. Currently I am applying character embedding type as I want my model can learn some of misspelling words in the text that is possibly happen during the OCR text extraction. This is the details configuration on my model architecture:
Performance Evaluation
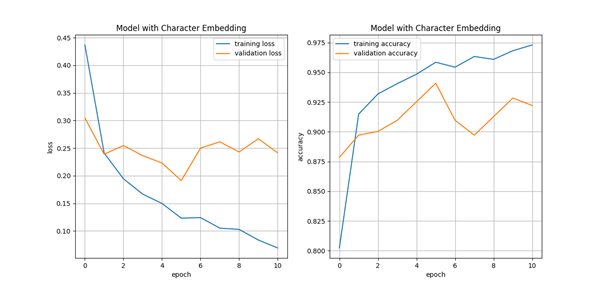
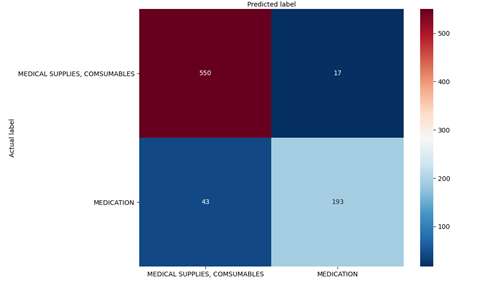
After training the model, the performance for the training and validation (loss and accuracy) shows that the model keep improving up until 5th epochs before it start to overfit. This is due to several reasons since we are not using any pre-trained embedding layers and our text corpus is not big enough to make the model generalized. By evaluate the confusion matrix, there are 60 misclassified samples was found with the F1-score accuracy 93% where 95% for “Medical Supplies and Consumables” and 87% for “Medication”. What we can identify there are some redundant text used in both classes that cause confusion in the model prediction. For example, the word “syringe”, “ml”, “mg” used in both classes.

Conclusion
There are several improvements can be done in my current work in handling 2 classes text classification model. Since I have imbalanced samples especially for “Medication”, we can apply some data augmentation technique to improve the current performance. We can apply word or characters augmentation in the original text by applying replacing synonym to the words, swap the position between words or even randomly insert characters. Pre-trained embedding also can be applied in the current architecture as we can leverage the training process. Other than that, model architecture especially the convolutional and LSTM layers used and hyperparameters model also can be tuned.