I was assigned to the Smart Traffic Light Project since January, In this post, I’m going to wrap up all the things that I’ve done for the past 7 months.
Introduction
Traffic congestion problems have existed for a long time now. One way to solve the problem is through traffic signals. Traffic signals also have undergone changes due to technological advancements. From time-controlled traffic lights, which used timing to change the signals to actuated traffic lights, which used sensors that detect the presence of vehicles and use the information to control the traffic signals.
Initially, the sensors used were inductive loops, planted under the road pavement to detect vehicles through the magnetic field. Later on, with the advancement of video detection and digital image processing, smart cameras were installed on the traffic light for vehicle detection.
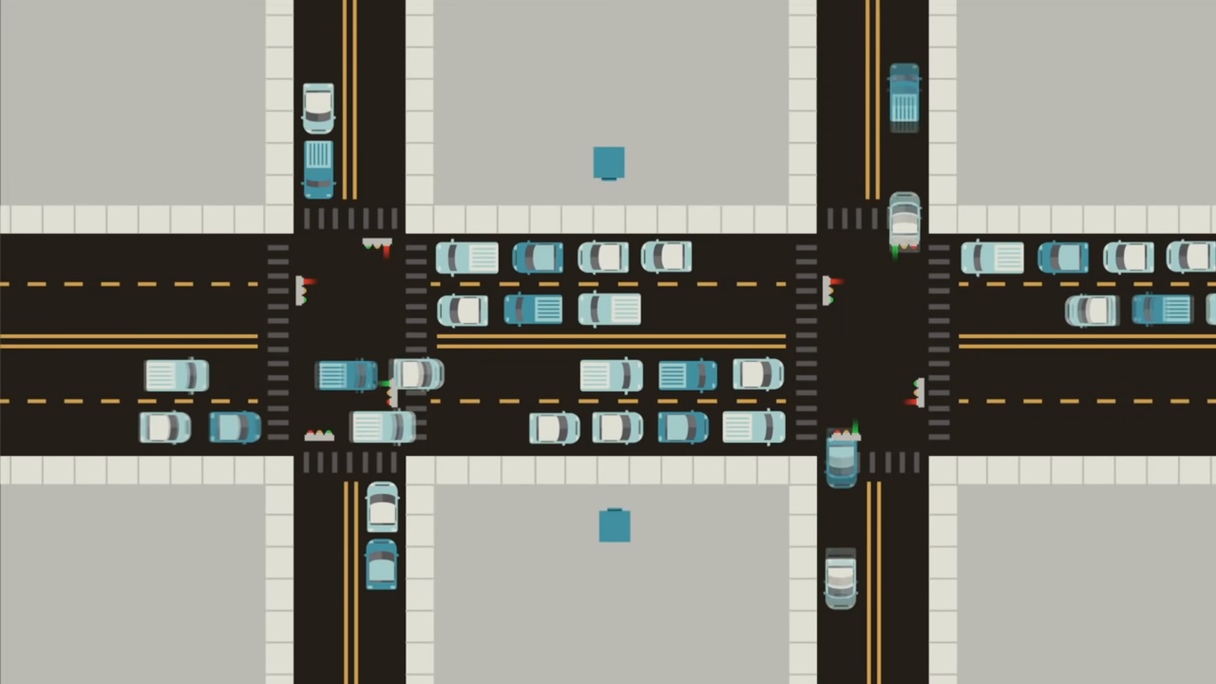
However, actuated control isn’t the end of the complexity. After all, it still treats each intersection as an isolated entity, when in reality each signal is a component of a larger traffic network. Take the classic example of two signals closely spaced in a row on a major roadway as shown below. If one signal gives a green but the next one doesn’t, cars can back up. If they back up far enough, they can sit through multiple cycles at an intersection without being able to pass through until the light beyond clears.

One solution to this problem is signal coordination where lights can not only consider the traffic waiting at their intersection but also the status of nearby signals. This is called adaptive traffic lights, and by implementing machine learning algorithms into the traffic light control system, a smart traffic signal control system is introduced.
Deep Reinforcement Learning Agent
In this project, deep reinforcement learning is used to train the agents to control the traffic signals. A typical scenario of deep RL is shown below.
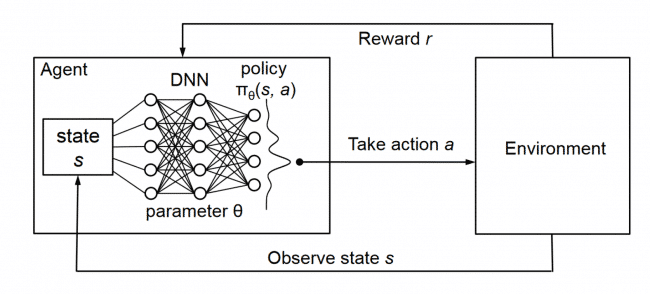
Before training the RL agent for a traffic light system, several basic concepts in RL need to be known first.
- State: the state describes the current situation inside the environment. For this project, it observes the position of vehicles and the current traffic light phase inside the environment.
- Action: the action is what an agent can do in each state. Given the state, the agent will choose the next traffic light phase from 4 possible predetermined phases.
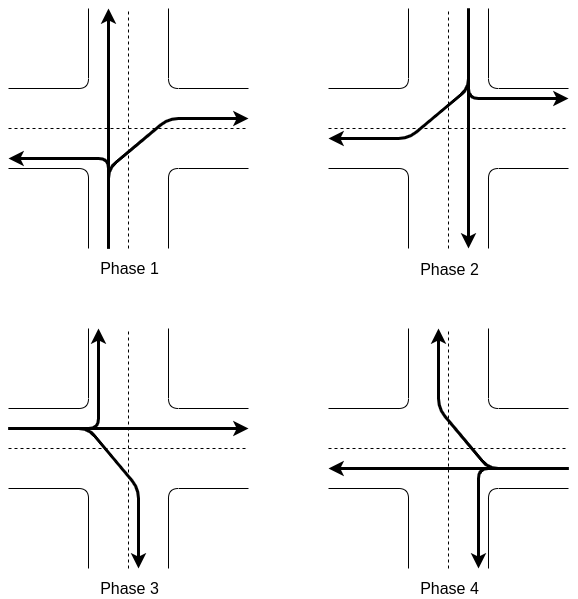
- Reward: the reward is an abstract concept that describes the feedback from the environment after the agent takes an action. The reward is the change in cumulative waiting time between actions in seconds. Cumulative means that every waiting time (negative reward) of every car located in an oncoming lane is summed. When a car leaves an oncoming lane (i.e. crossed the intersection), its waiting time is no longer counted. Therefore, this translates to a positive reward for the agent.
Deep Reinforcement Learning Environment
In this project, Eclipse SUMO (Simulation of Urban MObility) is used as the environment to train the RL agent. It is an open source, highly portable, microscopic and continuous multi-modal traffic simulation package designed to handle large networks.
To train the RL agent with SUMO, at least 2 files from SUMO are needed.
- Net file: SUMO net file is the road network that is created using SUMO. For the training purpose, the road network created using SUMO must resemble as close as possible to the road network in real life. SUMO has a python script that converts OpenStreetMap into the SUMO network, but it often produces inaccurate traffic directions, lanes and traffic light phases. The best way to create a SUMO network is by referring to Google Maps. Below is an example of a SUMO road network created based on a junction of Jalan Bukit Gambir, Pulau Pinang, in Google Maps.

- Route file: SUMO route file defines the traffic demand for a given SUMO net file. In this file, the number of vehicles, types of vehicles, vehicles spawning and movement direction, randomness of vehicle spawning and so on must be defined. The more randomness is introduced inside the environment, the more closely it resembles real life scenarios, theoretically.
Reinforcement Learning Algorithm
There are many RL libraries, but the one used in this project is mainly RLlib. Selection of RL algorithms is also important to ensure that the agent can maximize the cumulative rewards. Figure below is the beginner’s guide on choosing suitable algorithms for different projects with different purposes.
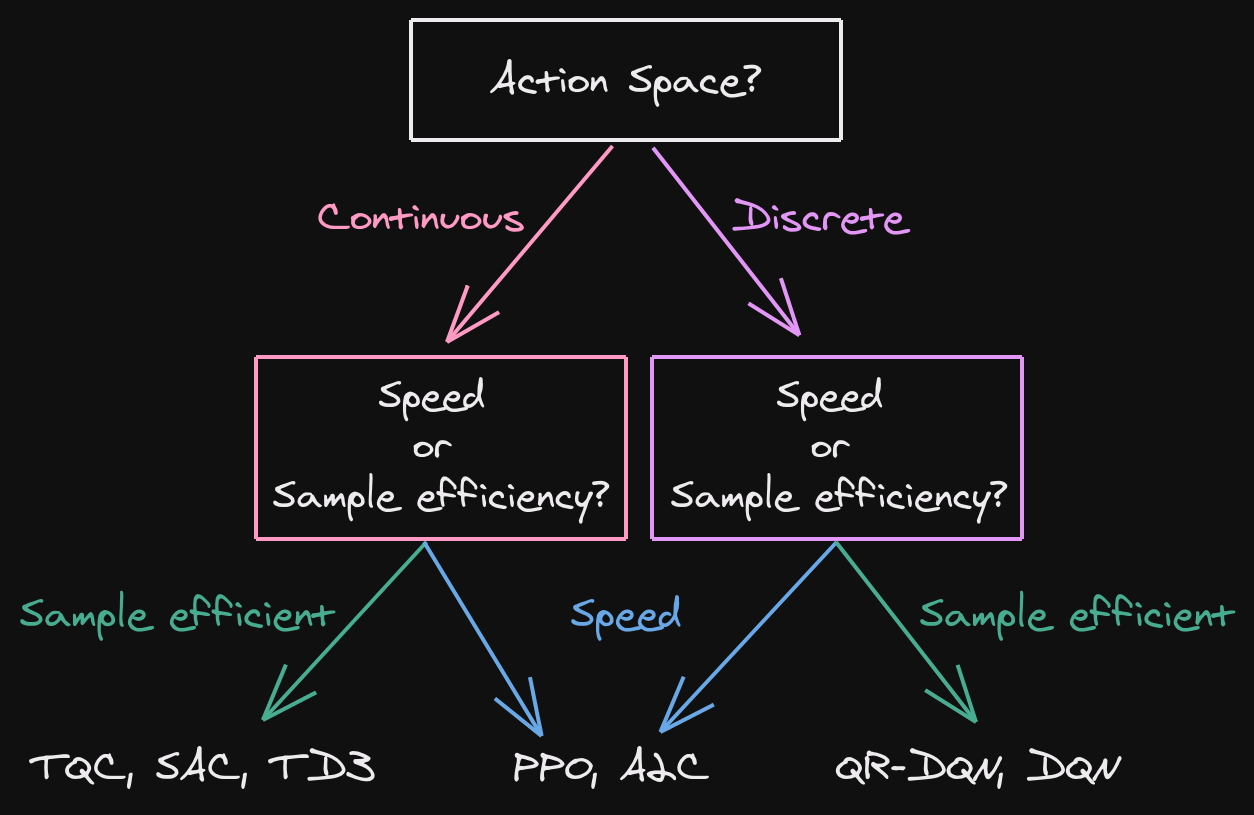
Source: https://stable-baselines3.readthedocs.io/en/master/guide/rl_tips.html#which-algorithm-should-i-use
Depending on the complexity of the environment, the algorithms that can be used for traffic light systems are either DQN (simple road network) or PPO/A2C/A3C (complex road network, multiple intersection).
DQN is usually slower to train (regarding wall clock time) but is the most sample efficient (because of its replay buffer). It also gives higher long-time rewards.
PPO/A2C/A3C shall be used if the wall clock training time is important (faster training). It can also help parallelize the training.
Agent Training
The process of training an RL agent is actually quite simple, but needs a long-time monitoring and evaluation to get the best results. For this project, SUMO-RL is useful as it provides a simple interface to instantiate Reinforcement Learning environments with SUMO for Traffic Signal Control. Follow this repository to learn how the agent is trained.
Results
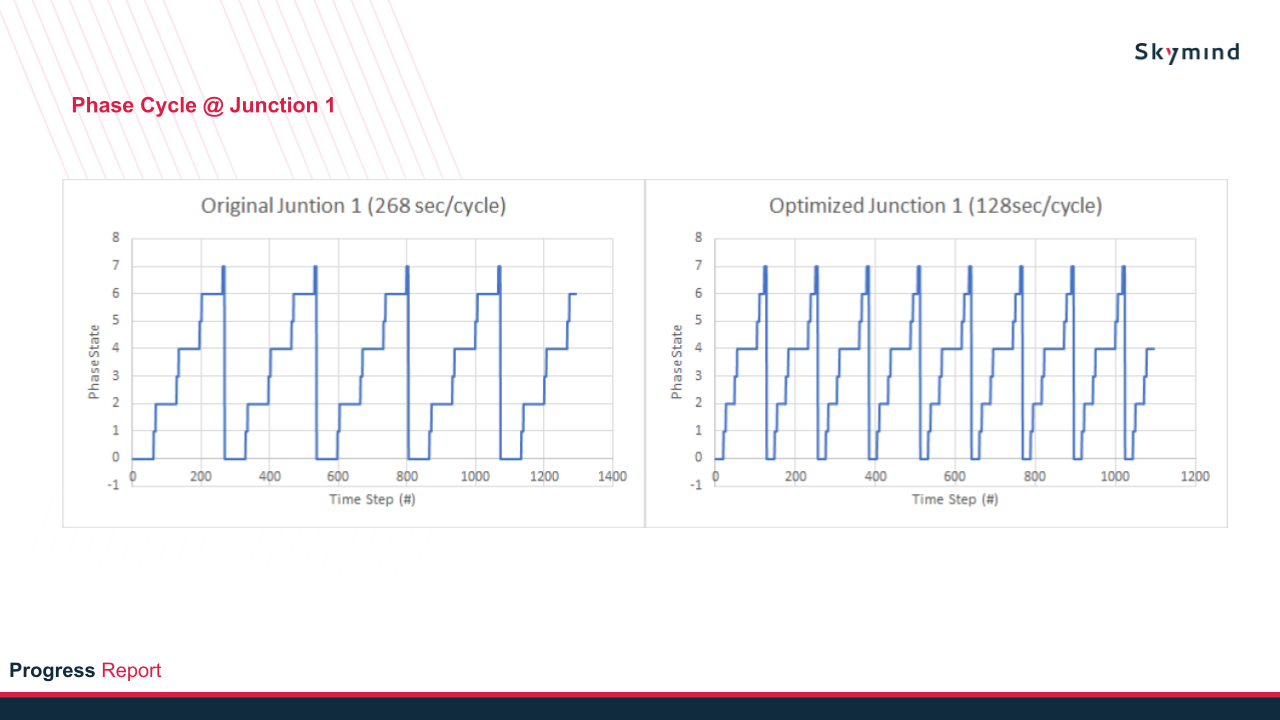
The results will be the comparison between the original traffic light vs optimized traffic light in terms of queue length, queue time, and phase cycle as shown below.

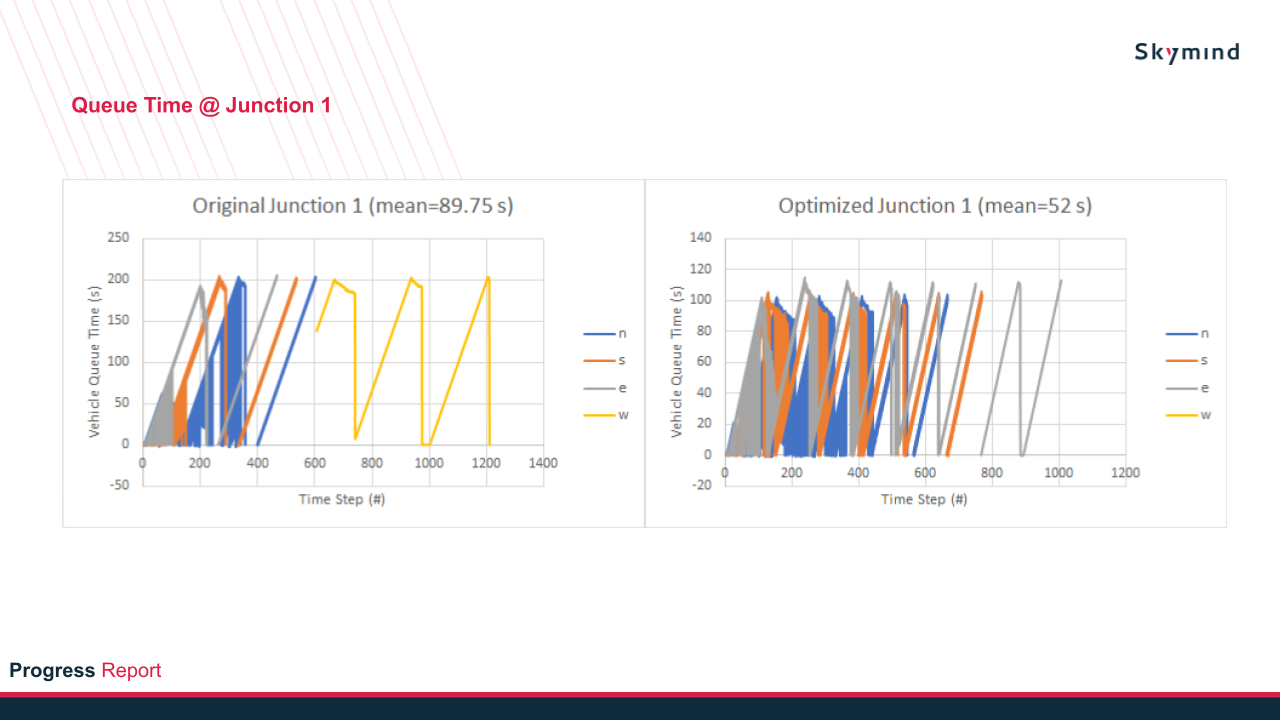
Among these results, queue time is the most important aspect to look at, since the RL reward depends on the cumulative waiting time of vehicles at all junctions at the traffic light. As observed from Figure 7, the queue time has slightly decreased in the optimized traffic light compared to the original traffic light.
In addition, depending on the timing setting of the traffic light and also the number of traffic light programs, it can be constant or varying at each phase cycle. Figure 8 shows a constant phase state at each phase cycle (128sec/cycle). Another test example was created where the traffic light has multiple programs with different timings, and the result is shown below.
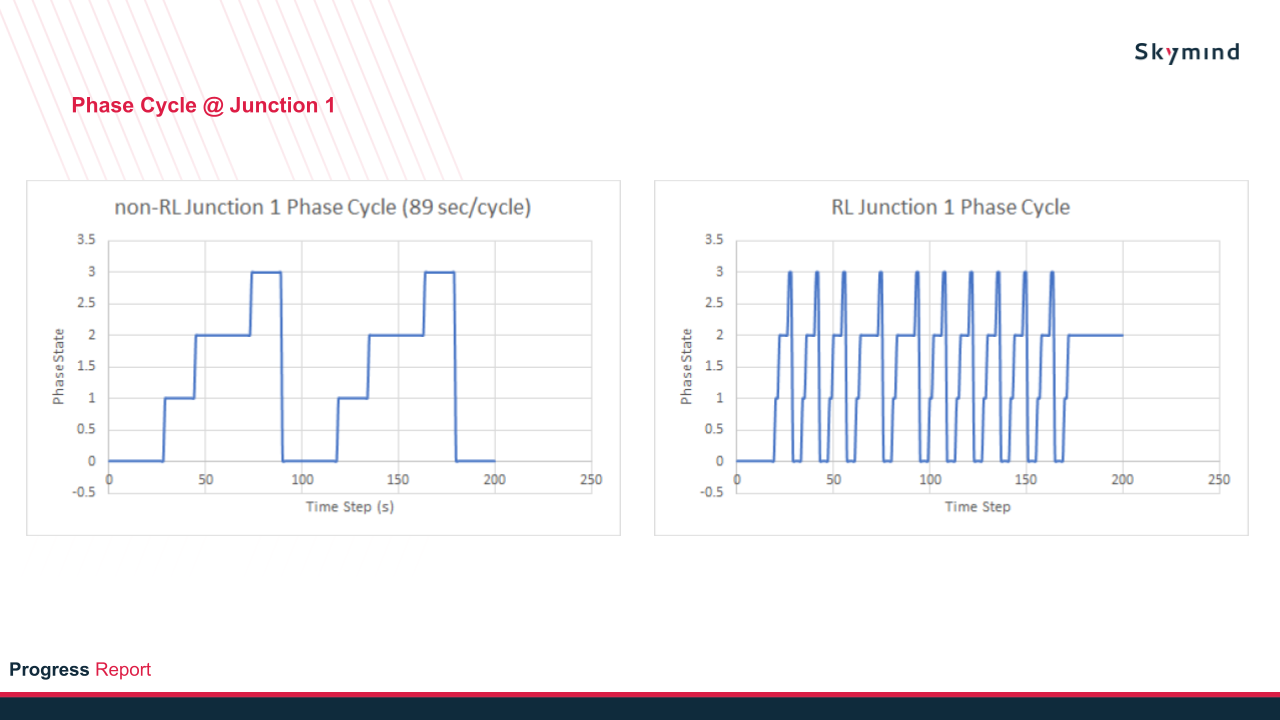
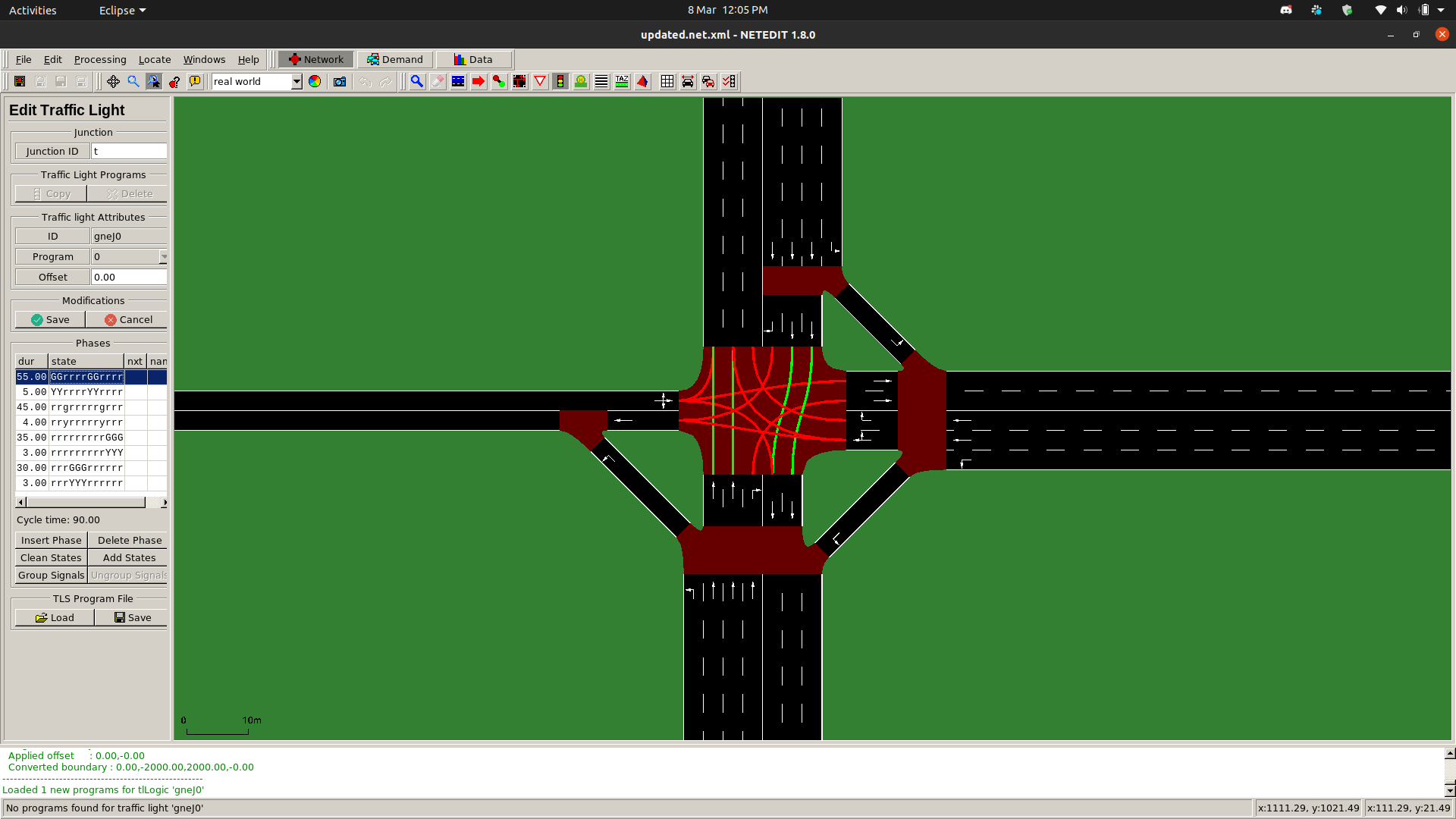
The RL agent will choose a suitable traffic light program depending on the traffic load at the specific time interval. The traffic light program can be initialized with SUMO netedit when editing the traffic light.
Conclusion
Thus ends the RL part of this project. There’s another part for this project where I use CARLA Simulator to train the vehicle detection model for the smart camera. Then integrate and synchronize both CARLA (for vehicle detection) and SUMO (for RL agent) to complete the function of the smart camera, theoretically, but that ends halfway as the project was discontinued. Maybe I’ll make a Part 2 if I have the time to explain about the CARLA part, and also, to elaborate further about the advancement of traffic light technology and traffic light sensors in a different post. Anyway, thanks for reading this.