
I was working on the continuation of a task related to GAN. There was a post about GAN which briefly explained about the introduction of Generative Adversarial Network (GAN) Model so, I guess I will skip the introduction part.
The purpose of this research is to look into ways of generating large scale dataset from fewer samples by augmenting them using controllable GAN.
Apprentice Project (Bird Generator)
During my apprenticeship, I made a generator for the purpose of data augmentation, it’s about generating random birds from different species. The generator I used is stylegan proposed by Karras et al. (2019).
Quick result from my bird model:

Setup and Details:
- Environment used - konsole
- GPU used - Tesla V100-PCIE-32GB then Tesla T4 (not multiple gpus, the gpu changed during konsole downscale)
- Image Final size - 128x128
- Time taken (training only) - 6 days 8 hours 49 mins 19 seconds
- Dataset size - 11788 samples with size of 224x224
- Loss used - wasserstein loss
Deployed using Google Cloud Platform and Flask framework. Click here
Difference between traditional GAN and StyleGAN
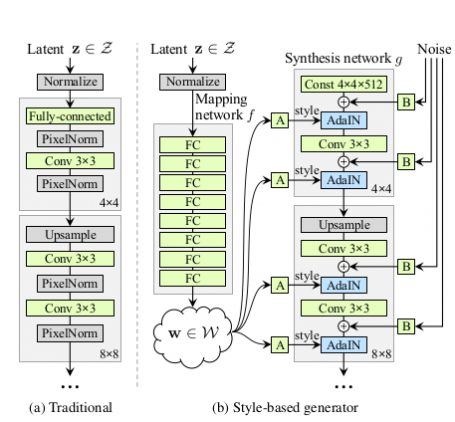
Traditional GAN consists of multiple typical upsample blocks from latent or noise Z and then the latent z will straight away go through upsample until the last block which outputs image. While StyleGAN consists of several important components which are:
- Mapping layer
- Noise injection
- Adaptive instance normalization (AdaIN)
- Progressing Growing
Mapping layer is done after generating random noises. The noise Z will be mapped to a few FC layers to create intermediate noise W. This method will make the noise less entangled.
Noise injection is done before the AdaIN. This noise reduction is intended to create more diversity to the image. The noise is injected to the image tensor.
Adaptive instance normalization (AdaIN) is meant to increase control over the image. It takes the image tensor (xi) and creates an instance normalization of image tensor and multiply it by style scale(ys) and add style bias (yb). These two ys and yb are calculated from intermediate noise W.
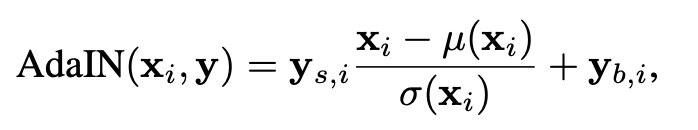
AdaIN formula
Lastly, progressive growing is a method in which we scale the image tensor from smaller image to bigger scale progressively. The typical image sizes of stylegan progressive growing is 4 -> 8 -> 16 -> 32 -> 64 -> 128 -> 256 -> 512 -> 1024. This method is intended to increase the quality of images.
Pokemon Synthesis (Failed ditto experiments)
Before bird generator, I did one experiment on a pokemon dataset specifically pokemon in Kanto’s region. This experiment also uses stylegan. This experiment is trying to imitate Ditto move “Transform”.
Quick Result:

Yeah, it was very bad. One of the reasons is that the dataset contains so much variation. With so much variation but little samples produces uncertainty. Pokemon has different types and many unique designs. My thought is, if we can reduce the variation, for example we train only on grass type pokemon, it might work. Then, I tried the bird generator because they share the same characteristics as a ‘bird’. The only difference is their species.
Proliferative Retinal Image Synthesis
Other than that, I did an experiment on fewer samples of a dataset which is a retinal image that has a proliferative level of diabetic retinopathy. The total samples are 708.
Quick result:

This experiment didn’t perform very well, one of it is because the model fails to generate the veins in the retinal in detail.
Original sample:

Current Experiment : fat to thin transformer using pix2pix
This is my current task now, not finished yet, multiple experiments need to be done. This experiment aims to transform fat people to thinner versions of themselves. I managed to collect 480 paired images from subreddit “progresspics”.
The experiment that I have done are:
- Training a full body transformation for 100 epochs and 100 epochs decay
- Training a full body transformation for 1000 epochs and 200 epochs decay
The results are worse than worst for now :


Future experiment:
- Face only transformation
Feel free to comment or make some suggestions!