The purpose of these posts is just to bring a reader up to speed on how to perform SER. But before that, let’s start with a brief introduction on emotion recognition.
Emotion recognition is a part of affective computing - the study and development of systems and devices that can recognize, interpret, process, and simulate human affects. The objective is simple - bridge the gap between human emotions and computational technology.

There are numerous ways to perform emotion recognition. The most popular one out there is through visual information – if a person is grinning the computer will recognize that the person is “happy”, when the person looks downwards, he may be upset. But that methodology doesn’t always work – a person may be smiling but inside he’s sad. This method can also be intrusive – can you really emulate your emotions in front of a camera?
Another method is using NLP. So whatever you say, the machine would take it literally. You can say, “I’m happy happy happy”, and the computer would take it that you’re happy. But again, that method doesn’t always work – you may say that that you’re fine, but inside you’re crying.
So in speech emotion recognition (SER), we take a different approach. Instead of taking what a person is saying at face value, we analyse the speech signals of the speaker, in hopes of finding the patterns of emotion. So it doesn’t matter what you say, as long as you speak to an SER system, it should be able to detect your emotions.
…and that’s usually how I pitch the speech emotion recognition idea in tech. expos. In reality there’s tons more variables and shortcomings to consider, some which I will outline throughout the blogpost.
SER has tons of already exiting publications, and the numbers keep growing. I took the search results of the number of IEEE papers related to SER, and it looks roughly like this:
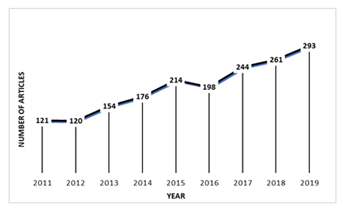
So what exactly motivates the huge boom of papers? If I had to say, it would be the low hanging fruits. There are so many speech features to try, hyperparameters you can tune, new architectures and models, a lot of the datasets are publicly available. It’s a pretty comfy research topic if you’re a graduate research student.
The overview of a general SER system can be viewed in the figure below. In the following blogposts, I’ll be elaborating more in each step.

A. Pre-processing
In this step, the raw speech signals go through a pre-processing. You can do a lot of signal processing techniques on the signal. For data collected in noisy places, you can pass the speech through a filter to remove background noise. Some include adaptive filter, Kalman filter, sub-band coding, wavelet transform, etc [2]. The opposite is also sometimes applied, where noise is introduced to the clean speech dataset to improve generality.
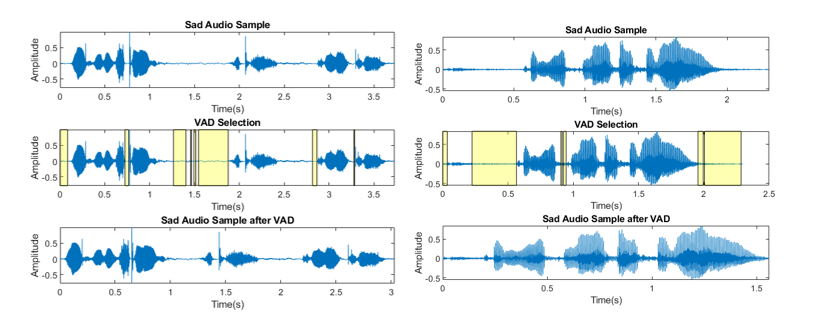
One method I employed previously was using Sohn’s Voice Activity Detection (VAD) algorithm to filter out unvoiced regions [3]. The showcase of using VAD is shown in the figures below.
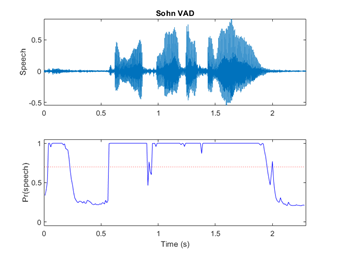
The result showed a great improvement especially when dealing with a noisy environment or you have considerable periods between each speech signal. That way, you can focus the feature extraction on the speech signals itself. After passing the emotion voice sample through a VAD, I resampled the signal that has a probability higher than 0.7 to be a voice sample, as shown below.
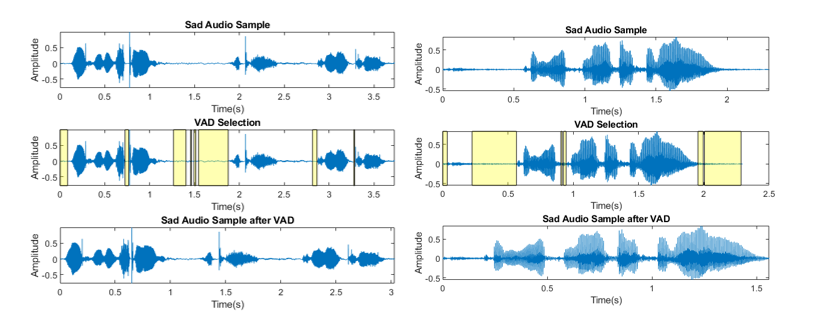
One thing to note - not every model filters out the noise and non-voiced region. The non-voiced region, for example, is a popular parameter to work on in depression detection, and noise is sometimes good if you want to deploy it in the real-world setting.
And that’s all for today’s blogpost. In the upcoming one, I’ll talk more about the features you can extract, since it’s a large topic to write about.
References
[1][T. S. Gunawan, M. F. Alghifari, M. A. Morshidi, and M. Kartiwi, "A Review on Emotion Recognition Algorithms using Speech Analysis," Indonesian Journal of Electrical Engineering and Informatics (IJEEI), vol. 6, no. 1, pp. 12-20, 2018.](http://section.iaesonline.com/index.php/IJEEI/article/view/409)
[2][M. Haque and K. Bhattacharyya, "Speech Background Noise Removal Using Different Linear Filtering Techniques," 2018, pp. 297-307.](https://www.researchgate.net/publication/325622133_Speech_Background_Noise_Removal_Using_Different_Linear_Filtering_Techniques)
[3][M. F. Alghifari, T. S. Gunawan, S. A. A. Qadri, M. Kartiwi, and Z. Janin, "On the Use of Voice Activity Detection in Speech Emotion Recognition," Bulletin of Electrical Engineering and Informatics, vol. 8, no. 4, 2019.](http://beei.org/index.php/EEI/article/view/1646)