
Supercharging Vecto with OpenAI and Qwen2 Model Support
The world of vector databases is evolving rapidly, and today we’re thrilled to announce significant enhancements to Vecto’s automatic vectorization capabilities. As we continue our Advent Calendar series of updates, Day 5 brings exciting news for developers and organizations looking to streamline their vector search implementations.
As the cornerstone of the Xpress AI platform, Vecto revolutionizes how developers interact with vector databases. We’ve eliminated the traditional complexity of vector operations by making the entire process automatic and intuitive. Instead of wrestling with embedding generation and vector mathematics, you can work directly with your data in its natural form - whether that’s text or images. This approach dramatically simplifies vector search implementation, making advanced AI capabilities accessible to developers of all experience levels.
Automatic Vectorization: The Foundation of Efficiency
At Vecto’s core lies our commitment to simplifying vector operations. While other solutions require manual handling of embedding generation, Vecto handles vectorization automatically, allowing you to focus on building remarkable applications rather than managing technical complexities.
Expanding Our Model Universe
Today’s update introduces support for three powerful new options in our vectorization pipeline: Qwen2 and both the small and large variants of OpenAI’s V3 embedding models.
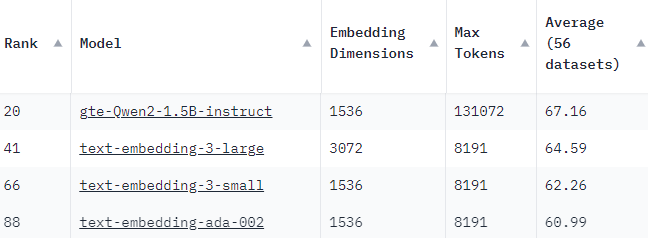
OpenAI Embedding Models
We’re introducing support for OpenAI’s latest embedding models, available in both small and large variants. These models excel at:
- Capturing nuanced semantic relationships
- Processing multilingual content effectively
- Delivering state-of-the-art embedding quality
Qwen2: Open-Source Power
Additionally, we’re proud to announce integration with the Qwen2 open-source model, offering:
- Superior long-text processing capabilities
- Great multi-language performance
- Cost-effective embedding generation
- Flexible deployment options for various use cases (i.e. it is the model of choice for an on-prem deployment)
We have selected the 1.5B variant of Qwen2 because it offers a best in class performance at a great processing speed.
Deprecations
As we introduce the new models, we are now also deprecating the SBERT and old OpenAI models that were available previously. They will continue to work for anyone who has used them before, but we suggest that you use the new models for any new projects.
Real-World Implementation: Documentation Search
To demonstrate these capabilities in action, we’ve implemented these new models in our own documentation search system. Experience the power of automatic vectorization firsthand by trying our enhanced documentation search, where you’ll notice:
- More accurate search results
- Improved handling of technical queries
- Faster response times across the board
Try Vecto’s enhanced search capabilities now using the search results on https://docs.vecto.ai and https://docs.xpress.ai.
Looking Ahead
This update represents another step in our mission to make vector search accessible and powerful. Stay tuned for more exciting announcements in our Advent Calendar series, as we continue to enhance Xpress AI’s platform capabilities.
Ready to experience these improvements? Visit our documentation to explore the new features, or sign up for a free account to start building with Xpress AI today.
- Start building for free → https://xpress.ai/join-waitlist