
Introducing Llama4S: A Scala 3 Llama 3.x Inference Engine
Large language models (LLMs) have revolutionized artificial intelligence, but implementing them to be highly performant while maintaining development scalability remains a formidable engineering challenge. At XpressAI, we are excited to introduce our latest project, Llama4S, which attempts to address this challenge.
Llama4S is a simple yet highly practical Llama 3.x inference engine written in Scala 3, designed to be lightweight, high-performance, and adaptable. Inspired by the llama3.java project, which itself draws from Andrew Karpathy’s llama2.c and his lectures on implementing LLMs, our approach prioritizes creating a lean implementation that balances computational efficiency with code clarity, pushing the boundaries of what’s currently possible in AI model inference.
Below is a screenshot of Llama4S in action:

The Rationale for Scala 3
Scala 3 provides a powerful foundation for Llama4S, offering developers an elegant, expressive, and scalable language to implement LLM algorithms. The language’s advanced type system and functional programming capabilities enable more robust and concise code compared to capabilities offered in more popular programming languages. Features like union types, opaque types, and improved pattern matching allow for more precise type-level modeling of complex machine learning abstractions, reducing runtime errors and improving code maintainability.
At the same time, the JVM ecosystem brings crucial advantages to machine learning infrastructure, including mature profiling tools, robust garbage collection, and just-in-time (JIT) compilation that can dynamically optimize performance-critical code paths. Scala’s seamless interoperability with Java means developers can leverage both existing Java and Scala libraries and tools, creating a rich ecosystem for machine learning development.
Furthermore, Scala 3 comes with advanced metaprogramming and compile-time code generation capabilities, which we believe has the potential for enabling large scale distributed LLM applications on the JVM. Macro and inline features allow for sophisticated code transformations and optimizations that can be resolved at compile-time, potentially reducing runtime overhead and enabling more complex model architectures without adding burden to the developers.
As such, Llama4S serves as a playground for exploring state-of-the-art possibilities in machine learning on the JVM, demonstrating how modern programming languages can push the boundaries of AI/ML frameworks design.
Performance and Implementation Challenges
Llama4S supports fast general matrix-vector multiplication for quantized tensors through the Java Vector API (JEP 469), which introduces SIMD-level programming capabilities to the JVM. The code also leverages additional advanced optimizations provided by the GraalVM compiler for optimal performance when compiled under it.
Since both Llama4S and llama3.java compile down to the JVM, their performance characteristics are comparable. For reference, we have included the llama3.java performance chart here for its comparison to llama.cpp, currently the most widely-used C++-based LLM inference engine:

However, despite the availability of JEP 469, we observed that its current implementation in the JVM struggled to optimize away vectorization-related bytecode outputted by the Scala compiler. Our investigation uncovered surprising insights into how method placement and language-specific implementation details can dramatically affect runtime performance.
Below are three performance traces, each profiling slight variants of the same vector dot product operation on Q4_0 tensors.
All code was run with the Llama-3.2-1B-Instruct-Q4_0 model
on a 2019 MacBook Pro with 2.3 GHz 8-Core Intel Core i9 processors and 16GB RAM.
In the code corresponding to the first trace, the vector dot implementation was defined inside the Q4_0Tensor class as an instance method:

Here, the JVM failed to optimize the SIMD lane shape-casting operation, with this bottleneck consuming roughly 90% of the computation time. As a result, the inference engine could only output tokens at a rate of roughly one token per 5 seconds, rendering the implementation impractical for real-world use.
In the code corresponding to the second trace, the implementation remained the same, with the exception that it was defined outside the Q4_0Tensor class as a static method:
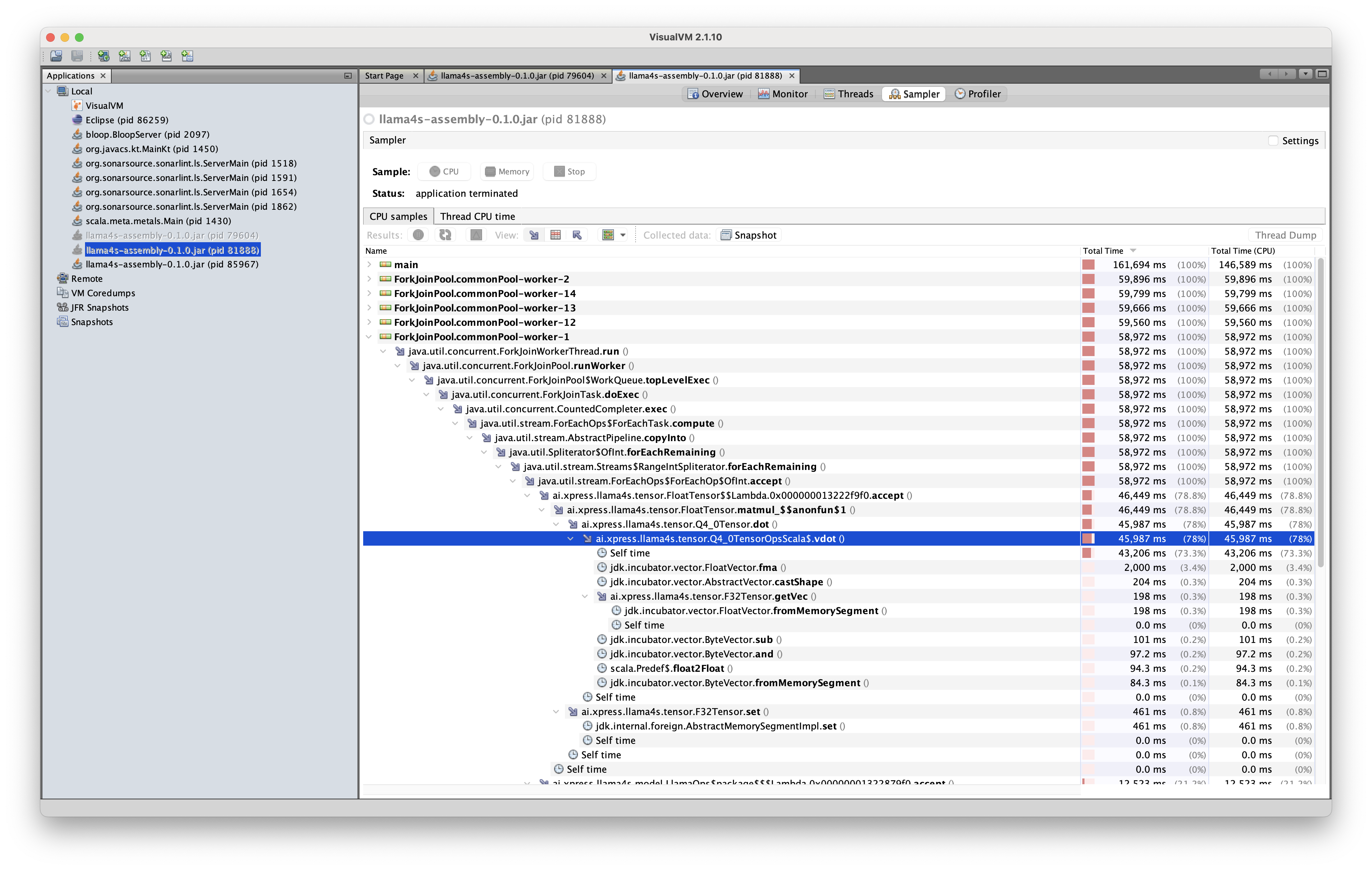
Remarkably, the shape casting operations were optimized away in this implementation, and the inference engine was able to output tokens at a rate of roughly three tokens per second. The performance was slightly further improved when the implementation was defined as a static method in Java instead:
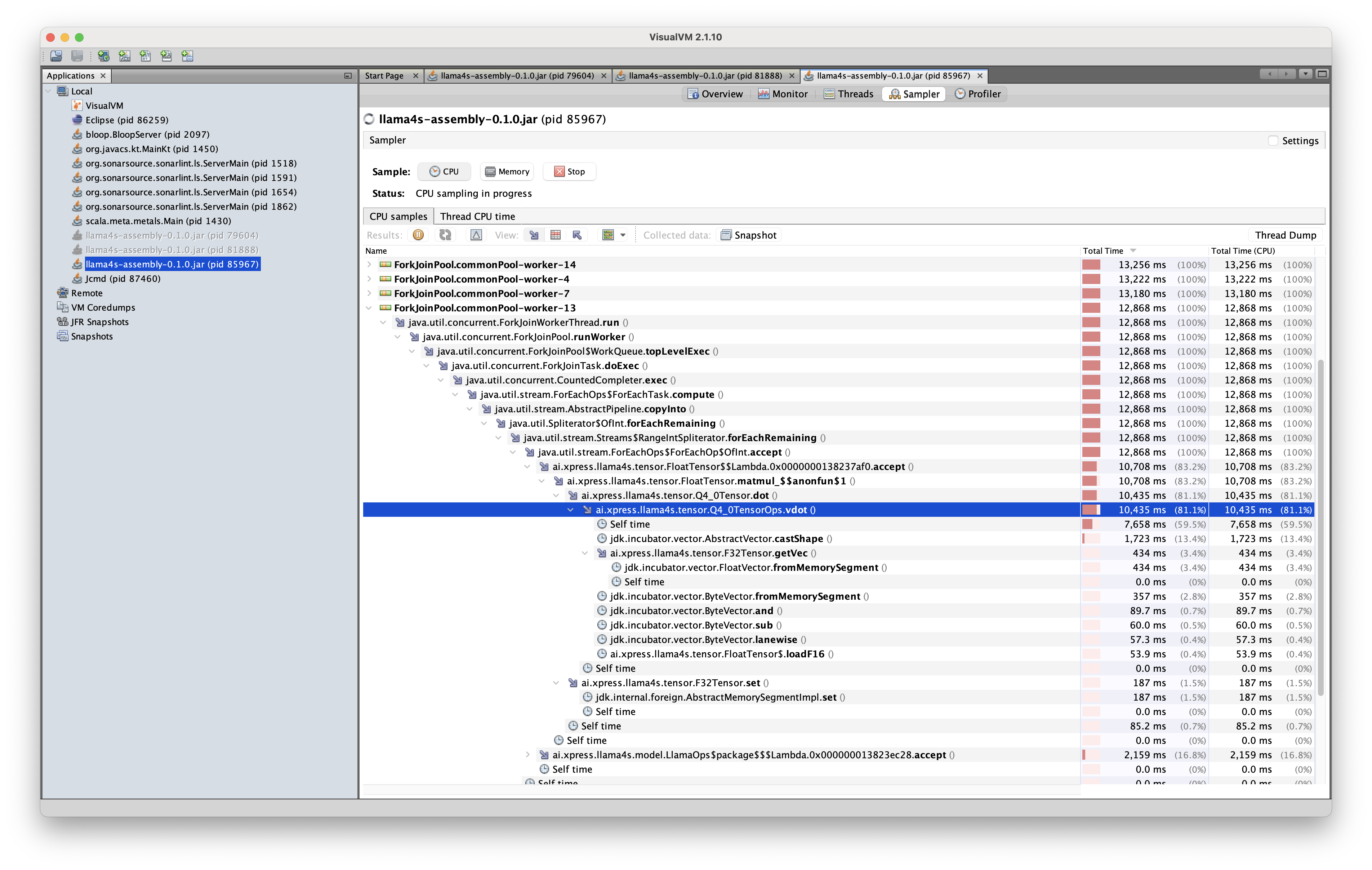
With this code change, the token output rate improved to five tokens per second.
These experiments demonstrate that while modern programming languages and APIs provide powerful tools for performance enhancement, achieving optimal performance requires a much deeper understanding of compiler behaviors and runtime characteristics than what the tools expose. Although we are using the Java Vector API as intended, the JVM has yet to fully be able to identify and optimize away code patterns involving its usage.
Future Work
Llama4S represents more than just another implementation of an LLM inference engine. It embodies a strategic exploration of how modern programming languages and runtime environments can be leveraged to push the boundaries of machine learning infrastructure. By choosing Scala 3 and embracing the JVM ecosystem, we’ve not only created a reasonably performant inference engine, but also opened up new avenues for distributed machine learning systems development.
Looking ahead, we see several exciting pathways for Llama4S:
- Better Vectorization: Our performance traces highlight opportunities for improving JVM vectorization strategies. We aim to share our findings with the broader OpenJDK community to help improve the implementation of the Java Vector API.
- JavaCPP Integration: We’re exploring the use of JavaCPP to create high-performance bindings with existing native libraries in the machine learning space, which will allow Llama4S to fully leverage the hardware in the areas of LLM inference where the Java Vector API may be insufficient.
- Distributed LLM Capabilities: Scala 3’s metaprogramming features provide a promising foundation for developing scalable, distributed machine learning frameworks. Llama4S will serve as a testbed for exploring these capabilities.
- Broader Model Support: While Llama4S is currently focused on the Llama 3.x models, we plan to expand support for a wider range of LLM models.
- Community Engagement: By open-sourcing Llama4S, we hope to foster a collaborative environment where developers and researchers can contribute to and learn from our implementation.
We invite developers, researchers, and AI enthusiasts to explore the Llama4S repository, contribute their insights, and join us in reimagining the future of machine learning infrastructure.
Despite its infant stage, Llama4S has aready been proving its value in real-world applications, as it is powering several projects at XpressAI. Stay tuned for upcoming demonstrations of Llama4S in action through our Xpress AI and Agents Advent series!