
This blogpost explains what pose-estimation is and gives an introduction on AlphaPose.
When we mention poses, we usually talk about how a person positions their body in different scenarios. Below we have 2 pictures of 2 different people standing in different ways. On the left, we see a football (soccer) player (Eden Hazard) have his arms bent slightly inwards while creating a bit of separation between his arms and main body. His knees are also slightly bent and his shoulders have been dropped. His right leg is more bent than his right and is off the ground, while he uses his left leg as his standing leg.


On the right however, we see a stormtrooper positioning his body differently. His right arm is parallel to the ground and straight, his shoulders are not slouching, his legs are straight to give him a perfectly upright position and he maintains a sufficiently large distance between his feet.
Understanding their poses, in this case standing, is important in knowing what actions are happening. The football player is prepared to dribble and turn in multiple directions while the stormtrooper is giving himself stability through a wide stance when shooting his gun.

What we hope to achieve with pose estimation is hopefully a connection of all the key joints in their bodies to understand their movements. On the left we see all the individuals in the image have their key joints/points in their body connected, telling us what they’re doing in the image.
There are 2 main approaches to pose estimation. We call them the top down and bottom up approaches. The top down approach starts with the detection of the person or body parts, followed by a regression model to predict the position of joints/features in the detected bounding box. The bottom up approach on the other hand attempts to detect all key joints/points in a person first, before connecting the detected points to form that person’s pose.

There are many good different open-source pose estimation architectures available, but I’ll focus on just the best one that is widely commonly used today.
AlphaPose, a top down approach to pose estimation which also happens to be the first open-source system that achieves 70+ mAP (75 mAP) on COCO dataset and 80+ mAP (82.1 mAP) on MPII dataset. There are 3 different annotation formats that we can use to train AlphaPose, namely COCO (17 keypoints), Halpe 26 (26 keypoints) and Halpe 136 (136 keypoints).

Many top down approaches to pose estimation tend to not do well because it’s highly dependent on the accuracy of the person/part detector that’s used to detect parts/persons prior to detecting the keypoints in the bounding box. Most architectures tend to use some modified version of YOLO or R-CNN in detecting persons/body parts and suffer from small localization and detection errors. Notice how the image below on the right has a ground-truth bounding box (red) different from the predicted bounding box (yellow), while on the left we see many predicted bounding boxes being produced, leading to the detection of multiple poses. AlphaPose improves the accuracy of the bounding box and reduces the number of inaccurate bounding box predictions by implementing a single and regional multi-person pose estimation framework (SPPE/RMPE) as well as a new pose Non-Maximal Suppression (NMS) framework to eliminate redundant detections of persons/parts.


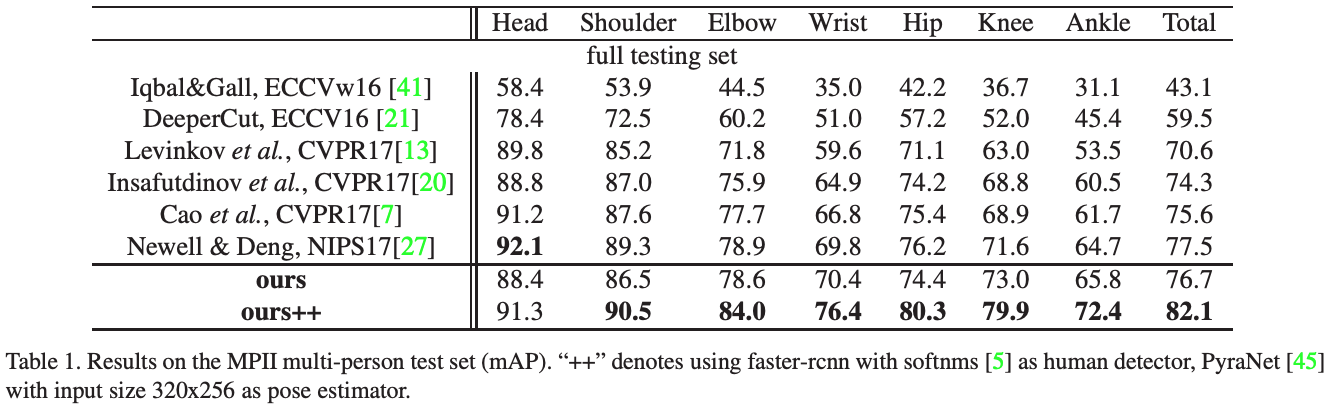
Above are just some of the results of previous state-of-the-art pose estimation models compared to AlphaPose. Notice how AlphaPose significantly outperformed other pose estimation models.
Nonetheless, AlphaPose still struggles in certain scenarios, listed below are just some of the success and failure cases of the architecture.

Even in very crowded settings the architecture does very well at detecting the poses of all the people in various images.

However, the architecture struggles when a rare/uncommon pose occurs in the image. In the first image on the very far left, the architecture has trouble detecting the “human flag” pose. When 2 people or more are highly overlapped, then the model struggles greatly in detecting the separate limbs of the people in the image. The misses of the person detector will also cause the missing detection of human poses (e.g. the person who has laid down in the third image). Finally, erroneous pose may still be detected when an object looks very similar to a human which can fool both the human detector and the SPPE (e.g. the background object in the forth image).